Sensitivity Analysis
Contents |
Purpose
Models can require many input variables in order to produce an output. While performing an uncertainty analysis of a model, the inputs are allowed to vary over a given range, and a variation of the model's output value is observed. A sensitivity analysis identifies which input variables are the predominate sources of the variation in the model's output. The scope of the sensitivity analysis can be restricted from across all inputs (global) to determining the sensitivity of a select group of inputs while holding the other inputs fixed (local). The complexity of the analysis increases proportionally to the complexity of the model. A model containing many inputs, non-linear relationships, or inequalities, will either experience either a difficult analytical sensitivity analysis or require other methods, such as Monte Carlo simulations.
Local Sensitivity Analysis
Local sensitivity analysis techniques employ the evaluation of partial derivative terms around an N-dimensional model calibration point. As such, these sensitivity measures are only applicable at the model point used; hence the term local. This method is best used in the model calibration stages of material model development as it allows for researchers to fine tune the parameters that have the greatest effect on model output and provide a basis for reducing calibration error. As stated, this measure is simply the raw numerical values of the partial derivatives of a model:
| ______________________________ |  , for , for 
|
______________________________ | (1) |
|---|
Where  is the model of interest and the
is the model of interest and the  's are the model inputs. However, each sensitivity measure for each
's are the model inputs. However, each sensitivity measure for each  cannot be directly compared due to issues with units. If combined model parameter input and output standard deviations, the local derivatives can be normalized using the input and output standard deviations:
cannot be directly compared due to issues with units. If combined model parameter input and output standard deviations, the local derivatives can be normalized using the input and output standard deviations:
| ______________________________ |  , for , for
|
______________________________ | (2) |
|---|
Where  is the
is the  th parameter standard deviation and
th parameter standard deviation and 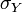 is the standard deviation of the model output subjected to variation of all parameters. These measures are called "sigma normalized local sensitivities" and allow for the direct comparison between parameters and their expected contribution to the model output variance. When derivative information is selected to be output from the UQSA tool and a Monte Carlo analysis of uncertainty is performed, the input and output standard deviations from model simulations are used to normalize the partial derivative terms. Otherwise, just the raw numerical values of the partial derivatives are output.
is the standard deviation of the model output subjected to variation of all parameters. These measures are called "sigma normalized local sensitivities" and allow for the direct comparison between parameters and their expected contribution to the model output variance. When derivative information is selected to be output from the UQSA tool and a Monte Carlo analysis of uncertainty is performed, the input and output standard deviations from model simulations are used to normalize the partial derivative terms. Otherwise, just the raw numerical values of the partial derivatives are output.
Global Sensitivity Analysis
Global sensitivity analysis measures seek to describe a parameter's overall effect on the totality of the model's output space. That is, these methods seek to asses the effect of the range of a given parameter on the output of a model. As such, this means effectively passing the entirety of the input statistical distribution through the model and analyzing the distribution of the output. There are multiple sensitivity measures within the scope of the global sensitivity analysis methodology namely:
- Total Effect Indices
- First Order Effect Indices
These methods generally rely on the Analysis of Variance (ANOVA) principle. The total variance of a model is broken down in to component variances that contribute to the total variance. This can be expressed as:
| ______________________________ | 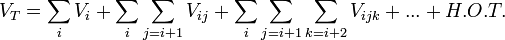
|
______________________________ | (3) |
|---|
Where 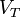 is the total variance of the model,
is the total variance of the model,  is the first order effect, or main effect, of variable , and
is the first order effect, or main effect, of variable , and  are the second order effects due to interactions between variables and
are the second order effects due to interactions between variables and  . The order of the effect increases with the number of the indices. The sensitivity indices are computed from these component variances by simply dividing by the total model variance.
. The order of the effect increases with the number of the indices. The sensitivity indices are computed from these component variances by simply dividing by the total model variance.
| ______________________________ | 
|
______________________________ | (3) |
|---|
The total number of individual terms that must be computed to quantify each interaction term scales as a power law:
| ______________________________ | 
|
______________________________ | (4) |
|---|
Due to this, it can be prohibitively computationally expensive to calculate each interaction term for even a moderate number of variables. To ease computation, generally two different indices are calculated: the first order effect index,  , and the total effect index. The current version of the UQSA tool is set up to calculate only the first order effects of each input parameter. Future versions will implement algorithms for the computation of total effect indices. The "First Order Effect Index" is represented by the equation:
, and the total effect index. The current version of the UQSA tool is set up to calculate only the first order effects of each input parameter. Future versions will implement algorithms for the computation of total effect indices. The "First Order Effect Index" is represented by the equation:
| ______________________________ | 
|
______________________________ | (5) |
|---|
Where  is the variance in model output varying only the parameter and
is the variance in model output varying only the parameter and  is the variance in model output varying all of the parameters together. This sensitivity measure assess the main contribution of a given parameter to the total variance of the model output and does not quantify the effects of interactions between parameters.
is the variance in model output varying all of the parameters together. This sensitivity measure assess the main contribution of a given parameter to the total variance of the model output and does not quantify the effects of interactions between parameters.
The UQSA tool uses two methodologies to assess the first order effect index of model parameters. A Monte Carlo random sampling algorithm is employed mainly for verification of other calculation techniques in this tool, but can be used for low dimensional models (less than 10 parameters) if desired. Another technique used for the computation of first order effects indices is the Fourier Amplitude Sensitivity Test (FAST) [1] which is implemented in this tool.
For the FAST sensitivity analysis method, all parameter ranges are represented as cyclic functions called "search curves." A uniform distribution search curve is used of the form[1]:
| ______________________________ | ![x\left(\theta\right) = x_{min} + \left( x_{max} - x_{min}\right) \left[ \frac{1}{2} + \frac{1}{\pi} asin\left(sin\left(\omega\theta + \phi \right)\right) \right]](../images/math/5/e/a/5ea2f5324f7991098980efe02081a51c.png)
|
______________________________ | (6) |
|---|
Where  is the maximum parameter value,
is the maximum parameter value,  is the minimum parameter value,
is the minimum parameter value,  is the parameter frequency, and
is the parameter frequency, and  is a random phase angle from 0 to 1. When randomly sampled, this function is approximately uniformly distributed. This enables us treat our model as a random, noisy signal. Using an N-dimensional fourier transform, we can then filter the model output and investigate the resulting frequency spectrum.
is a random phase angle from 0 to 1. When randomly sampled, this function is approximately uniformly distributed. This enables us treat our model as a random, noisy signal. Using an N-dimensional fourier transform, we can then filter the model output and investigate the resulting frequency spectrum.